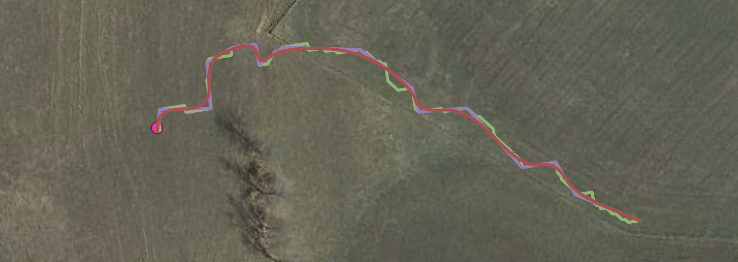
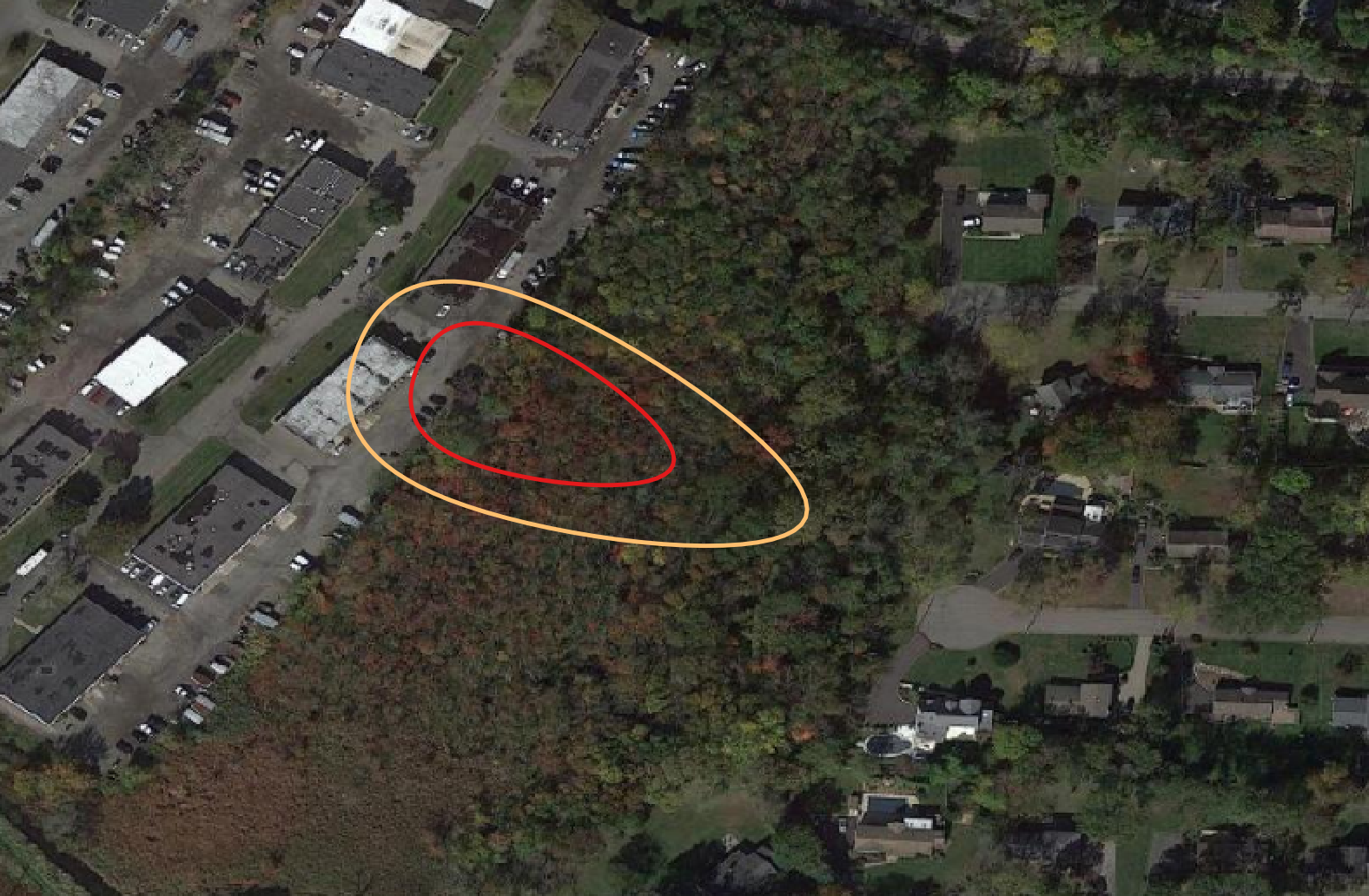
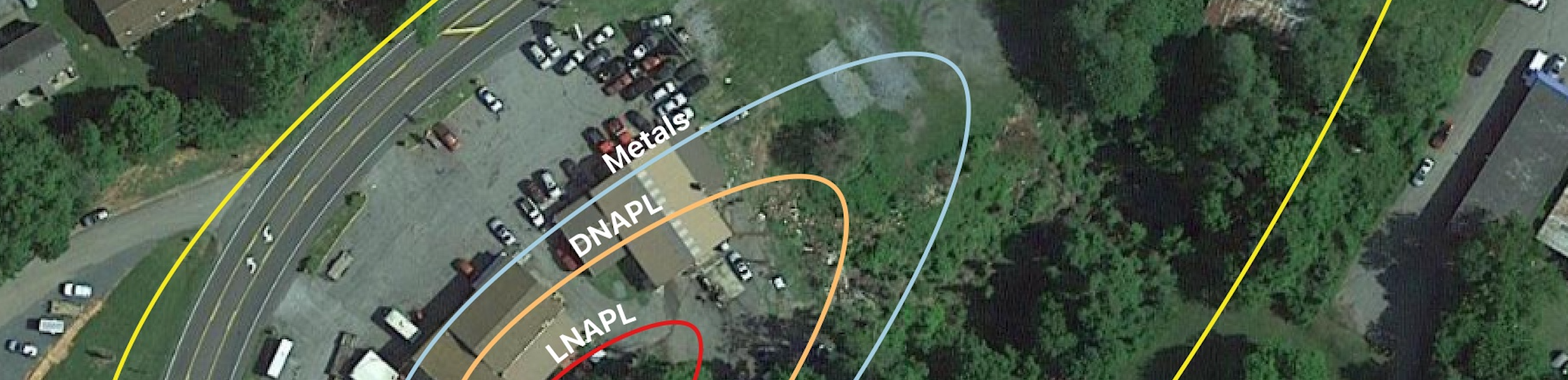
EnviMetric makes intelligent predictions about the extent of groundwater contamination even when there is no available analytical data regarding contaminant concentrations. Factors such as the site location, release type, property use, and geologic setting are very predictive of how large a groundwater plume will be.
EnviMetric uses all this available information to make data-based predictions of contaminant extent providing estimates such as “there is a 95% chance that the groundwater plume at this site is between x feet and y feet long.”
Our latest update:
For projects where the site investigation is further along and there are already multiple monitoring wells and groundwater samples EnviMetric can use this information to make more precise predictions of contaminant extent and it does this differently than traditional fate and transport modeling. Traditional fate and transport modeling often uses data from multiple locations at a site to “calibrate” theoretical models of contaminant transport. In layman’s terms you could think of this “calibration” for a hypothetical example site as saying something like:
The modified (to account for attenuation and sorption) advection-dispersion equation predicts that the plume should be 1,000 feet long and the concentration of TCE 100 feet from the source should be 10 µg/L; TCE at monitoring well #1 located 100 feet from the source is greater than predicted (let’s say it’s actually 15 µg/L instead of 10 µg/L) therefore we predict the plume to be greater than 1,000 feet (maybe that observation modifies the prediction to 1,250 feet)
EnviMetric is a machine learning model— it doesn’t rely on any particular theoretical model of fate and transport, rather it uses a solely data-based framework to predict what an unknown groundwater plume will look like based on how the site of the un-delineated plume relate to sites where the plume extent is already known.
Concentrations at multiple locations at a site are fed into this model just as all the other variables are. We leave it up to the machine learning algorithms to weight each variable based on how predictive it has been during training on known sites. This allows the data to speak for itself. Our database now includes over 1,500 sites with analytical data from multiple groundwater sample locations. Collectively, our database contains analytical results from over 17,000 monitoring wells and groundwater grab points. This large quantity of data allows our model to better differentiate the signal from the noise and understand how to make predictions about unknown groundwater plume extents based on limited analytical data at a site.
The bottom line?
-
The EnviMetric model uses a machine learning algorithm based on the data from thousands of contaminated sites to make a prediction about the most likely extent of underground contamination at a given site
-
The model takes into account site specific data provided by clients that has already been collected
-
Because the model is able to make predictions based on the EnviMetric database AND site specific data, application of the machine learning model can take place after site investigation has begun
-
This allows us to provide a new view into existing site conditions.† How likely is it that the contaminant plume is traveling off-site? Does a certain detection fit in with the pre-existing data set or could it be coming from an off-site source? What are some gaps in the site’s conceptual model that could require additional sampling? What could be happening in areas where sampling is difficult or impossible?
-
Applying the EnviMetric model once site investigation has already taken place can help with answering some of these tough questions
If you have a site that would be of interest or want to know more about the model grab a time with our team! or …